February 18, 2026
The AI Analyst Genome: Designing a Multi-Agent System That Rebuilds Itself From a Single File
How we designed a single markdown file that regrows an entire multi-agent AI data analyst from scratch. Architect debates, builder agents, and the blurry line between prompts and specifications.
I watched a system we spent the past week building get reproduced from a single file in about four hours. On a machine that had never seen the original code. No access to the source repo. No copy-paste. Just a 1,398-line markdown file and Claude Code with Opus 4.6.
The rebuilt system had different code. Different internal structure. But the same capabilities, the same agents, the same analytical pipeline. It was the same organism grown from the same DNA.
That’s the moment I stopped thinking of it as a prompt.
We (me, Hai, and Sravya) built an AI data analyst in about a week once Opus 4.6 dropped. A multi-agent system inside Claude Code. 17 agents, 30 skills, 26 Python modules. Around 35,000 lines of code and configuration. It takes any dataset, asks the right questions, runs the analysis, validates the numbers, builds the charts, writes the narrative, and produces a finished slide deck. The whole thing.
Then we started asking: what’s the minimum specification that could regrow all of it from scratch? Not a backup. Not a compressed version. The actual instructions for building the system, from nothing, in an empty repo.
That file is 1,398 lines of markdown. We’re calling it the genome.
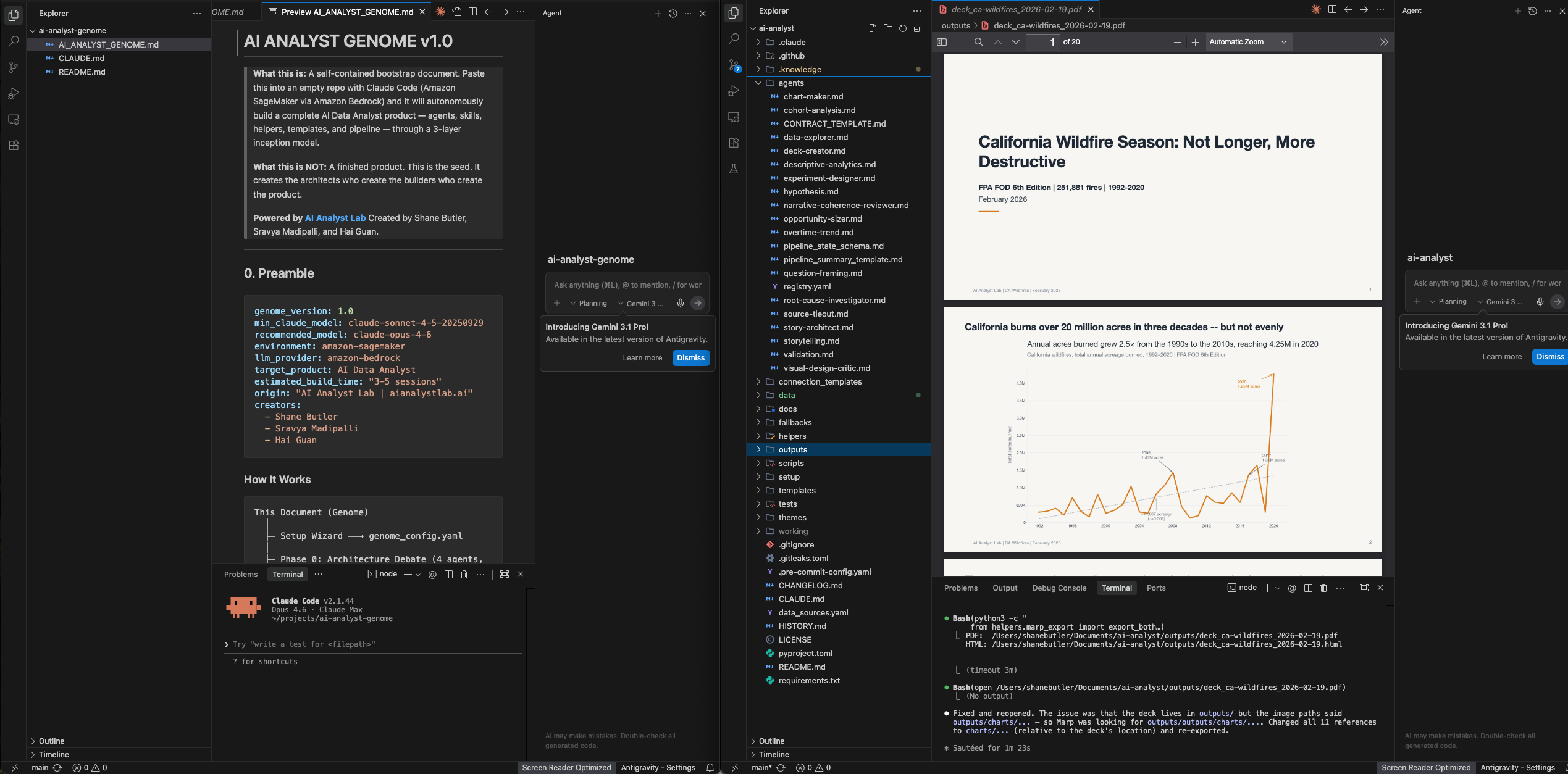
What the genome produces
Two repos, both public. The genome repo is the specification. One markdown file. The AI analyst repo is what gets built from it. 17 agents across a 6-phase pipeline, 30 skills that shape how every agent works, 26 Python helpers for data connectivity and chart rendering.
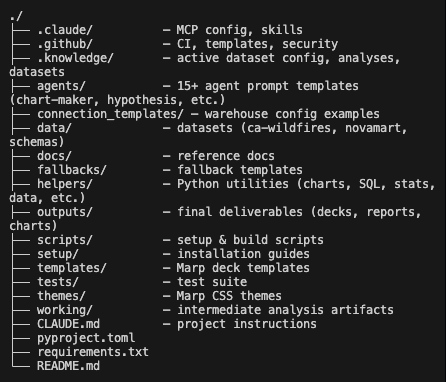
We wrote previously about what happens when you point the AI analyst at real data. This post is about the file that builds it.
The architect debate protocol
The genome doesn’t generate code directly. That was the part that surprised me most about how it turned out.
It creates architect agents first. Three of them. Each one has a completely different mandate. The Product Architect designs the system shape (directory tree, agent boundaries, data flow). The Quality Systems Designer designs everything about trust (validation layers, confidence scoring, review protocols). The DevEx Designer designs the user experience (how someone interacts with the system day to day, error handling, onboarding).
They each draft a proposal independently. Then they read each other’s proposals and annotate every section: AGREE, DISAGREE, or EXTEND. A fourth agent (the Build Arbiter) reads all three drafts plus all the disagreements, resolves every conflict using a priority system, and produces the canonical build plan.
The three original architects get a final review. They can raise blocking objections, but only if they cite a specific failure mode. Not “I don’t like this.” Cite the failure or stand down.
Then builder agents execute the plan the architects agreed on.
So the layers are: human creates genome, genome creates architects, architects debate and produce a spec, builder agents execute the spec and produce the product. Three layers of inception before any code exists.
Here’s what one of those architect definitions actually looks like in the file. This is the Quality Systems Designer:
AGENT: Quality Systems Designer
You are the Quality Systems Designer for an AI Data Analyst product.
YOUR JOB: Design validation, review, and testing strategy that ensures every
analysis is trustworthy.
PRODUCE:
1. 4-layer validation system spec:
- Layer 1: Data Quality (nulls, duplicates, out-of-range) — pre-analysis
- Layer 2: Statistical Rigor (appropriate tests, CIs, effect sizes) — during
- Layer 3: Logical Coherence (business sense, contradictions) — post-analysis
- Layer 4: Presentation Accuracy (charts match data, labels correct) — pre-output
2. Confidence scoring system (0-100, letter grades A-F, display as badge)
3. Review loop protocol (APPROVE / APPROVE WITH CHANGES / REJECT)
- Max 2 revision cycles before escalation
- Max 1 full rejection before user escalation
4. CONTRACT block schema (every agent must have one)
5. Registry validation rules (file existence, cycle detection, orphan check)
6. Acceptance criteria templates for each agent type
CONSTRAINTS:
- No heavy statistics: t-test, chi-square, CIs, and effect size are the ceiling
- Simpson's Paradox check is mandatory before any conclusion
- Validation agent must run before any findings are presentedThat’s not a prompt. Read it again. It has a 4-layer validation architecture. It specifies a confidence scoring system. It defines a review protocol with escalation conditions. It constrains the statistical ceiling. It requires a Simpson’s Paradox check before any conclusion reaches the user.
And this is one of four architects. Each producing specifications at this depth. For a system that doesn’t exist yet.
The Product Architect is simultaneously designing the directory tree, agent dependency graph, data flow diagrams, and integration points. The DevEx Designer is defining skill naming conventions, error taxonomies, onboarding flows, and a 5-level question routing system. All in parallel. All independently. Then they cross-review and argue.
How the genome encodes decisions
The file is 1,398 lines broken into 10 sections. Here’s the structure:
| Section | What it encodes | Lines |
|---|---|---|
| 0. Preamble | Version, model requirements, creators | 1-30 |
| 1. Setup Wizard | 7 questions that shape the system | 67-165 |
| 2. Architecture Debate | 4 agents, 4-round protocol | 177-375 |
| 3. Build Agent Definitions | Templates for builders | 376-550 |
| 4. CLAUDE.md Template | The system’s identity document | 551-700 |
| 5. Agent Templates | 17 agent specifications | 701-950 |
| 6. Skill Templates | 30 skill specifications | 951-1005 |
| 7. Quality System | Review loops, contracts, validation | 1006-1128 |
| 8. Build Tracking | Sessions, waves, error recovery | 1078-1128 |
| 9. Brand System | Colors, themes, templates | 1129-1398 |
I’ll walk through three sections that show why I think this file is a specification, not a prompt.
The setup interview. Before anything builds, the genome asks 7 questions. What data platform are you on. Describe your data. What’s the main question this analyst should answer. Who sees the outputs. What capability tier. Custom brand colors or default. Confirm and go.
Q1: Data Platform
> "Where does your data live? Tell me about your database or data warehouse,
> or if you're working with flat files."
> (Free-form — user describes their setup. Could be Snowflake, PostgreSQL,
> BigQuery, Redshift, Databricks, CSV/JSON files, or anything else.)
Follow-up:
> "Do you already have connector scripts or libraries that talk to your data?"
> - YES → "Point me to them — I'll inspect and wrap them."
> - NO → "I'll figure out what connection details I need based on your platform.
> What credentials or access method do you use?"Seven questions and the system grows differently depending on your answers. Different data platform, different connectors. Different capability tier, different agent count. Different audience, different communication style. The genome doesn’t build one system. It builds a family of systems.
The quality contracts. Every agent in the built system has to include a CONTRACT block. This is the meta-specification. The genome defines what the contract schema looks like, and every agent the builders create must include one:
<!-- CONTRACT_START
name: agent-name
version: 1
layer: 0 | 1 | 2
pipeline_step: N | null
inputs:
- name: INPUT_NAME
type: str | file | query_result
source: user | system | agent:upstream-name
required: true | false
outputs:
- path: working/output.md | outputs/output.md
type: markdown | csv | json | image | yaml
depends_on: [upstream-agent-names]
review_by: reviewer-agent-name | null
CONTRACT_END -->A registry assembler reads these contracts and builds a dependency graph. Before any pipeline execution, it validates: do all referenced files exist? Do all dependencies resolve? Are there cycles? Are there orphan agents? Do output types match downstream input types?
The genome doesn’t just tell builders what to create. It defines a contract system so the built agents can validate each other. Specifications that produce more specifications.
The build tracking system. The build takes hours. Multiple sessions. The genome handles this with a wave model and session protocol. Five waves, each completing before the next starts. Foundation first, then core infrastructure, then pipeline agents, then skills and UX, then integration testing.
Every session starts by reading BUILD_STATUS.yaml, computing the ready set and blocked set, and announcing where it left off. If more than 30% of a wave’s tasks fail, the system pauses and reports to the user. Failed tasks block their dependents but not the entire downstream tree. It picks up where it left off. It doesn’t redo completed work.
Whether the architect debate round actually improves the output versus just generating it in one pass… I honestly don’t know. We haven’t run the controlled experiment. It feels like it matters. The decision logs are richer. The edge cases get caught earlier. But I can’t prove it yet.
What the output looks like
We ran the genome-built system on 2.3 million US wildfire records from 1992 to 2020. The prompt: “How has wildfire season changed in California over the last 30 years?”
It produced a full analysis deck. Charts, narrative, recommendations. The entire pipeline ran. Question framing, data exploration, root cause investigation, validation, story architecture, chart production, deck assembly.
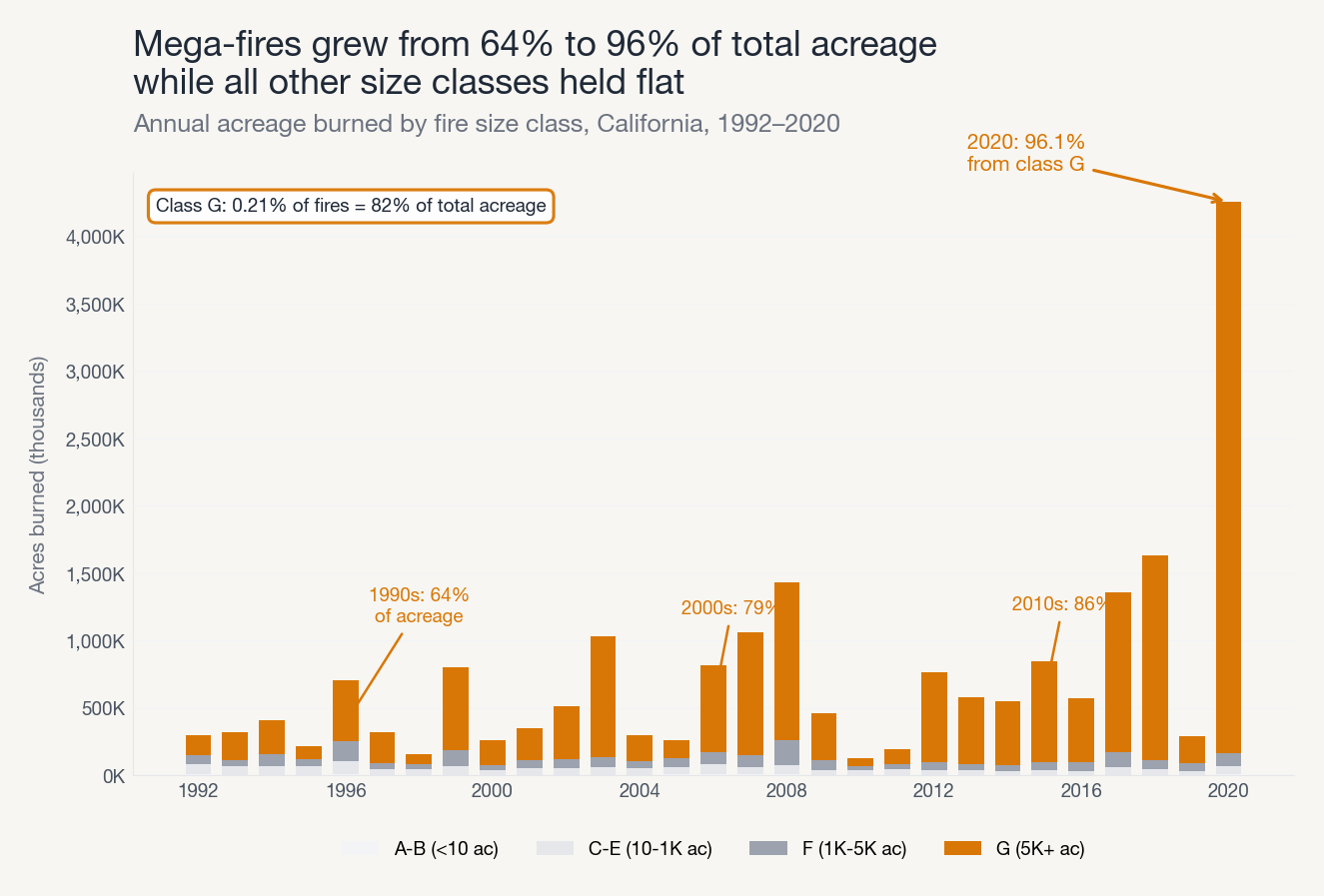
The system decomposed the trend by fire size class and found that 0.21% of fires (Class G, 5,000+ acres) account for 82% of total acreage burned. Every other size class held essentially flat for three decades. The entire growth story is mega-fires.
Then it drilled into 2020 specifically. Root cause investigation, seven layers deep.
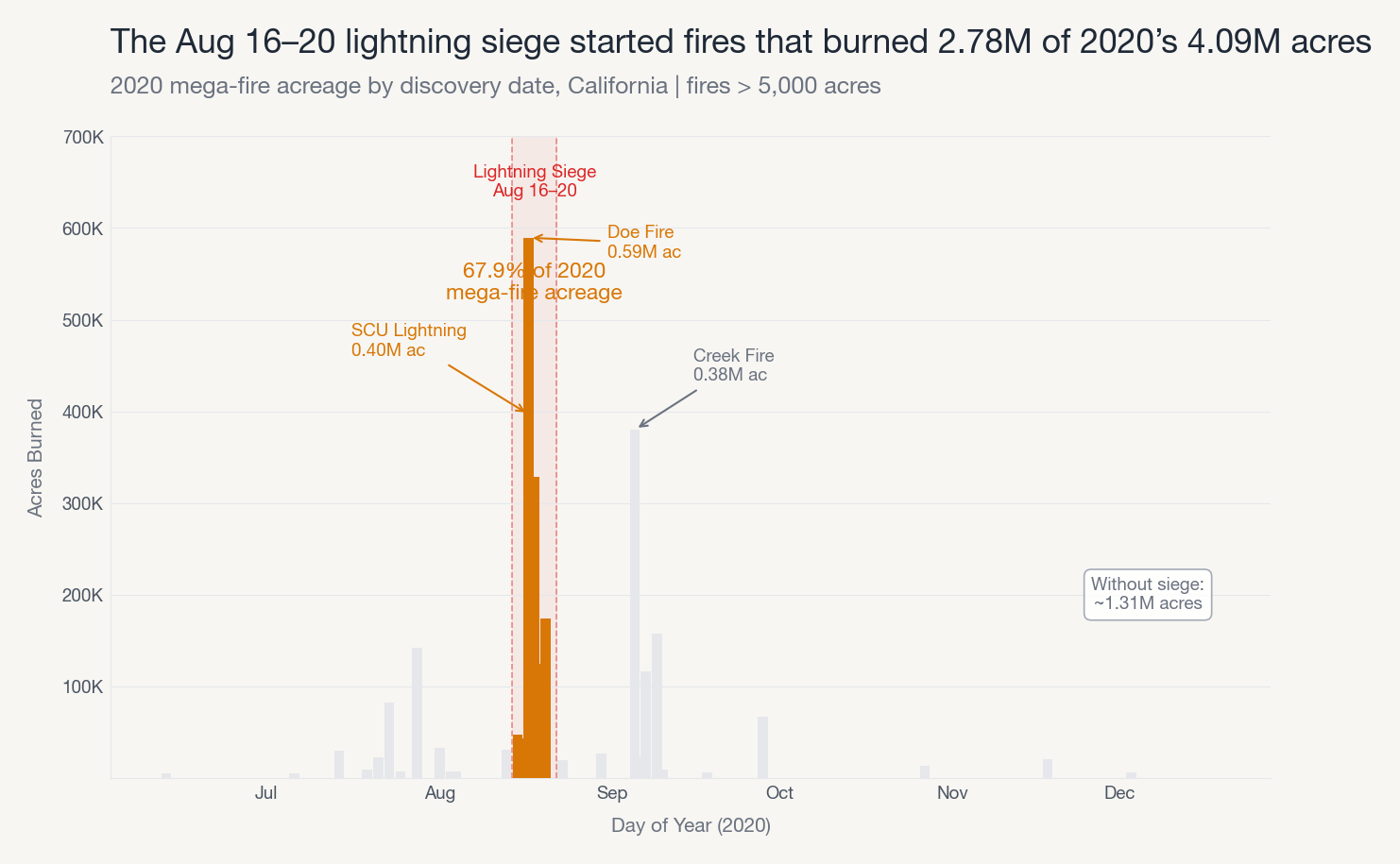
A single 5-day lightning siege in August 2020 started fires that burned 2.78 million of the year’s 4.09 million acres. The system identified individual fires by name, quantified each one, and calculated the counterfactual: without that one weather event, 2020 drops from historically unprecedented to a bad-but-normal year.
It takes hours to run. Like, actually hours. The genome builds the system over multiple sessions, and then each analysis runs the full 6-phase pipeline. We use Claude Code Max Plan (flat subscription) because usage-based billing on something this long would be painful.
The quality is genuinely good. The charts follow Storytelling with Data principles. Action titles, direct labels, gray-first-then-color. The narrative has a real arc to it. The recommendations are tagged with decision owners and follow-up dates.
It’s not perfect. Some chart annotations crowd on dense data. The narrative can lean corporate if you don’t tune the voice settings. But the baseline coming out of a system that rebuilt itself from a specification file… pretty wild.
When does a prompt become a specification?
I keep going back and forth on what to call this file.
It’s markdown. It has no executable code. You could open it in any text editor. In that sense it’s a prompt. A really long one.
But it has architectural decisions. Dependency graphs. Naming conventions. Error handling patterns. Quality gates. A contract schema that agents use to validate each other. A 4-round debate protocol with escalation conditions. A wave model for multi-session builds.
At some point “prompt” stops being a useful label. I don’t know exactly where that line is.
I look at this file and I honestly don’t know what to call it. It’s 1,398 lines of markdown. It produces 35,000 lines of working code, agents, skills, and configuration. The code it produces on Machine A is structurally different from the code it produces on Machine B, but the capabilities are the same. The specification is 25x smaller than the thing it creates.
A genome does not contain an organism. It contains the instructions for building one. And those instructions include creating the architects who design the build plan. There’s something in there I’m still trying to articulate. About what it means when a specification is sophisticated enough to produce architects that produce specifications that produce code. About where the design decisions actually live.
I don’t have a clean answer. I’m not sure there is one yet.
Try it yourself
Two repos, both MIT licensed:
- The genome: the single markdown file. Drop it into an empty repo with Claude Code.
- The AI analyst: the complete 35,000-line system the genome is based on. 17 agents, 30 skills, everything.
You need Claude Code with Opus 4.6. We recommend the Max Plan (flat subscription) because the build runs for hours. Sonnet produces a noticeably weaker system. The genome doesn’t abstract the model layer. That’s a real limitation.
Expect 3-5 sessions for a full build. Have an empty repo ready. Answer the 7 setup questions. Let it run.
If you try it on your own data, we’d genuinely like to hear what happens. Especially interested in cases where it fails.
This post describes the genome as of February 2026. The genome continues to evolve. See the repository for the latest version.
Want to learn how to custom build your own AI analyst? We’re running the Build AI Analysts in Claude Code bootcamp. Weekend intensive, 8 hours. You walk through the full build pattern from scratch and leave with a working system on your own data. Three instructors, real-time support.