February 20, 2026
The Correction System: What Happens When You Validate Every Number Your AI Analyst Produces
I manually validated every number my AI analyst produced against my own SQL. Found out I was the one who had it wrong. Then I started noticing what the correction log was turning into.
I Was Checking the AI’s Work
I spent a week validating every number my AI analyst produced. I wrote my own SQL, ran queries against the same data sources, and compared outputs side by side. Every number. I was checking.
I started with north star metrics. Revenue, adoption, engagement. Numbers I’d been reporting to leadership for months. Numbers I knew. I picked these deliberately. These were supposed to be the easy validation round, the metrics where you already know the answer because you wrote the original query and you’ve been staring at the graphs every Monday for three months and the number is just there in your head. If the AI could match these, I’d move to harder questions. If it couldn’t, nothing else mattered.
Every number tied out except one. I looked at my query, looked at the AI’s, asked it to explain the difference. It had found a bug in my SQL. Two table abbreviations swapped in a join, pulling data from the wrong tables. I’ve been a data scientist for over ten years. I picked those metrics because they were supposed to be simple confirmation. Instead the AI got the right answer and I had the wrong number.
The thing I built to check the AI’s work is what caught my mistake.
So I kept going.
It Made Mistakes. Then It Logged the Fix.
The next test was harder. I asked it to calculate our AI eval scores over time. The table had five or more date columns you could calculate over, and it picked the wrong one. It chose the timestamp for when the user submitted their input instead of when the AI output was created. (These aren’t the exact column names. But it went something like this.) The difference matters because you’re trying to measure the quality of the AI’s output, not the timing of the user’s request. Calculate over the wrong date and your trend line shifts, your windows capture different records, and your score tells a different story.
I didn’t tell it what was wrong. I asked it. I showed it the numbers didn’t match what I expected and asked it to figure out why. It looked at the date columns, compared them, and came back with the answer on its own. Wrong timestamp. It fixed the query.
Then I asked a different question. How do you not make this mistake again?
That’s when it built the correction log. Not just the fixed SQL. The full context: what the mistake was, what the fix was, the rationale, the severity, and a field that scopes the correction to situations where it’s relevant (something like “calculating eval metrics over a time window”). All of it indexed by table, column, and business concept. Written into a structured YAML file in the system’s knowledge directory, where every future session can find it.
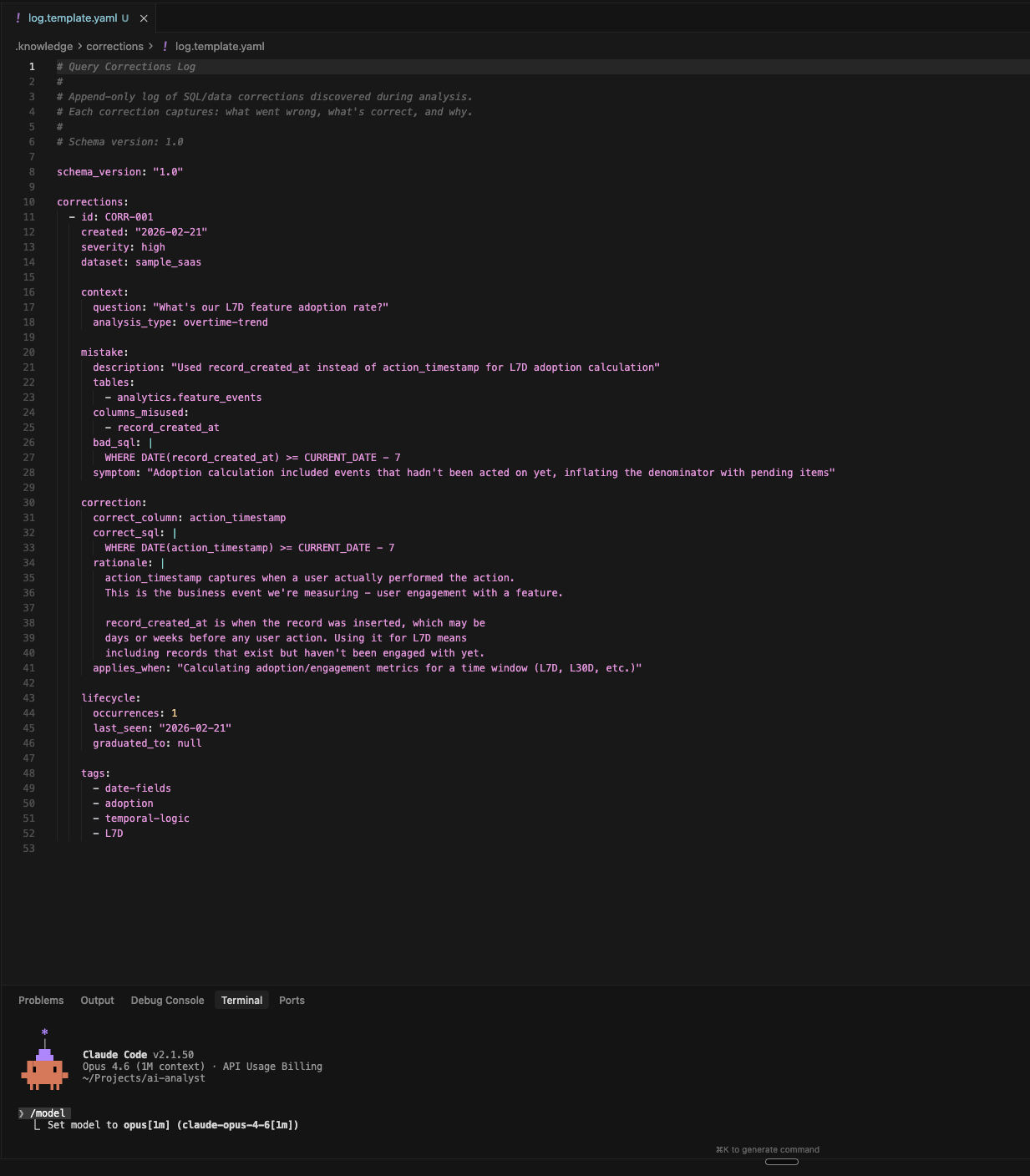
The next time any question touched that same area, the correction got applied before any SQL was written. The same column confusion didn’t come back. Not in the next session. Not in any session after that. Not because the model “learned” in some vague sense. Because the fix was sitting in a file that gets checked on every query, deterministically, before the agent writes a single line of code.
I started paying attention to that file.
Deterministic Lookup, Not Magic
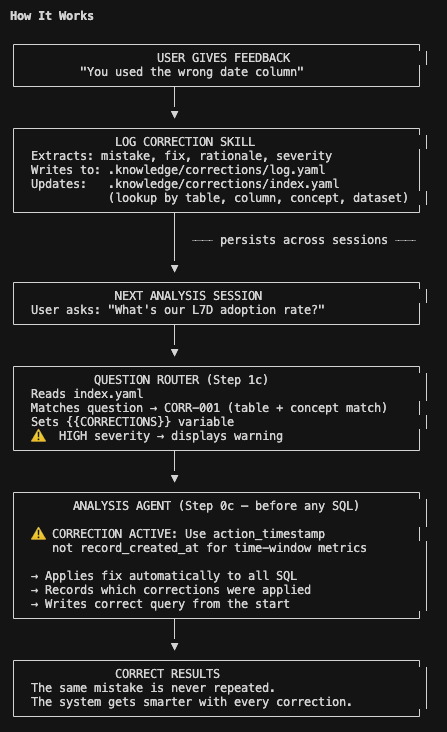
The mechanics are straightforward. I ask the system what went wrong and how to not repeat it. A skill extracts the structured correction, writes it to a log, and updates an index keyed by table, column, concept, and dataset.
Next session, I ask a question. The question router reads the index, pattern-matches the question against known corrections, and if there’s a match, injects the relevant correction into the analysis agent’s context before any SQL gets written. High severity corrections carry a warning flag. The agent sees the fix before it starts working.
No vector search. No embedding similarity. Deterministic lookup on structured metadata. Table name matches table name. Column matches column. The router handles the inference, figuring out whether a question about eval scores over time should trigger a correction about which date column to use, but once the match is made the application is mechanical.
I don’t know whether this holds at scale. We have maybe fifteen corrections in the file right now. What happens at 200? Do corrections start conflicting with each other? Do context-dependent fixes break the simple lookup when the right column depends on what type of question is being asked? I think there’s a ceiling somewhere. Haven’t hit it.
But I know what the file started to look like.
The Correction Log Started Looking Like a Semantic Layer
After a few weeks of correcting mistakes, I opened the log and the index file and just looked at them.
Each entry was mapping a business concept to specific physical data. “AI eval score over time” maps to the output creation timestamp, not the user input timestamp. “Active users” means users with at least one action in the window, not users whose records were created in the window. Each correction was a rule: use this column, not that one, for this type of question. The index was organized by table, column, and concept.
I recognized the shape. That’s a semantic layer. Or at least the start of one.
Analytics engineers spend months building these. They map business language to physical data, define which columns mean what for which metrics, codify the tribal knowledge that lives in people’s heads about which date field to use, which filter to apply, which join condition matters for which type of analysis. They build them in dbt, in LookML, in whatever semantic layer tool their company has standardized on. Careful, deliberate, documented engineering.
And here I was looking at something with the same shape, growing out of a correction log. Not because anyone planned it. Because every time the AI figured out what went wrong and logged the fix, it was encoding one more piece of the mapping that analytics engineers build on purpose. Each wrong number I caught and corrected added another row to a translation table between how the business talks about its data and how the data is actually structured.
The log grew into something I recognized. It grew for free. Nobody designed it. Nobody scoped it. Nobody wrote a project plan or got approval from a data governance committee. It just accumulated, one wrong number at a time, into something useful.
I keep going back and forth on whether the analogy holds all the way. A real semantic layer is tested, version-controlled, peer-reviewed by other engineers. The correction log is just corrections I made while asking questions. The rigor is different. The coverage is spotty. It only knows about the areas where I’ve asked questions and caught mistakes.
But the shape is the same. That’s the whole damn thing. The most valuable artifact in the system wasn’t the AI analyst. It was the file that taught it.
An Hour Arguing About Date Columns
I spent an hour arguing with the AI about which date column to use for time-window metrics. Another hour figuring out that one of our tables has timestamps that represent when a record was created in the system, not when the thing it describes actually happened. Use the wrong one and your time-window calculations quietly include records that don’t belong there.
That hour wasn’t the AI doing impressive work. That was me doing the same tedious data investigation I’ve always done. Column by column, join by join, looking at raw data and asking why this number doesn’t match what I expect. The kind of work that never shows up in a demo.
The difference is that the investigation got captured. Every correction, every “use this not that,” every piece of context about why a specific column matters for a specific type of question went into the file. The next person who asks about adoption metrics on that table gets the fix before they can make the same mistake. The next session where I ask a similar question gets the correction injected automatically. The investigation doesn’t live in my head anymore. It lives in the log.
Before the correction system, this kind of knowledge vanished. You’d find a bug, fix the query, move on. The fix lived in your head until you forgot it or left the company. Two months later, a new session or a new analyst would trip over the same column, make the same wrong assumption, report the same wrong number. The file changed that.
Nobody talks about this part because it’s fucking boring. An hour debugging date columns. But the file got longer. And the next analysis got more reliable. And the one after that. Every wrong number I corrected was a brick in something I didn’t set out to build.
The system isn’t getting smarter. The file is getting longer. From the outside, the effect is the same.
I Was Checking the AI’s Work
I started this to validate output. To make sure the numbers were right before I trusted them. I was checking the AI’s work.
Every check that caught a mistake turned into a correction. Every correction went into the file. The file started looking like a semantic layer. A persistent, growing map of how this business talks about its data, which columns matter for which metrics, which date fields mean what in which context. It grew for free, out of the validation work I was already doing, out of the wrong numbers I was already catching.
I don’t have a clean ending here because I’m still watching it grow. I don’t know if the simple lookup breaks at scale. I don’t know if the correction log plateaus somewhere short of what a real semantic layer provides. I don’t know if analytics engineering is really just “accumulated corrections, formalized” or if that’s a romantic simplification of something more rigorous.
But I know what happened. I set out to check the AI’s work. The checking became the building. Every wrong number was a brick.
Take whatever number you reported last week. Run the AI on the same question. Check its work. Check yours. When you find the wrong number, don’t just fix the output. Log the correction. Because the file you’re building might be worth more than the analyst you’re checking.
The AI analyst is open source. The genome repo is the specification file. The AI analyst repo is the full system. Both MIT licensed. If you run it on your own data and the correction system does something interesting (or breaks), I’d like to hear about it.